I have been using Google Earth Engine (GEE) for two years now. It was initially difficult to understand the interface, language, analysis and visualisation, but this became simpler over time. Time-series analyses, plots and animated gifs/videos are easy to implement in GEE. Recently, I also began exploring Microsoft Planetary Computer (MPC) for satellite imagery processing. During this process, I made some initial comparisons between GEE and MPC, which I’ve detailed below.
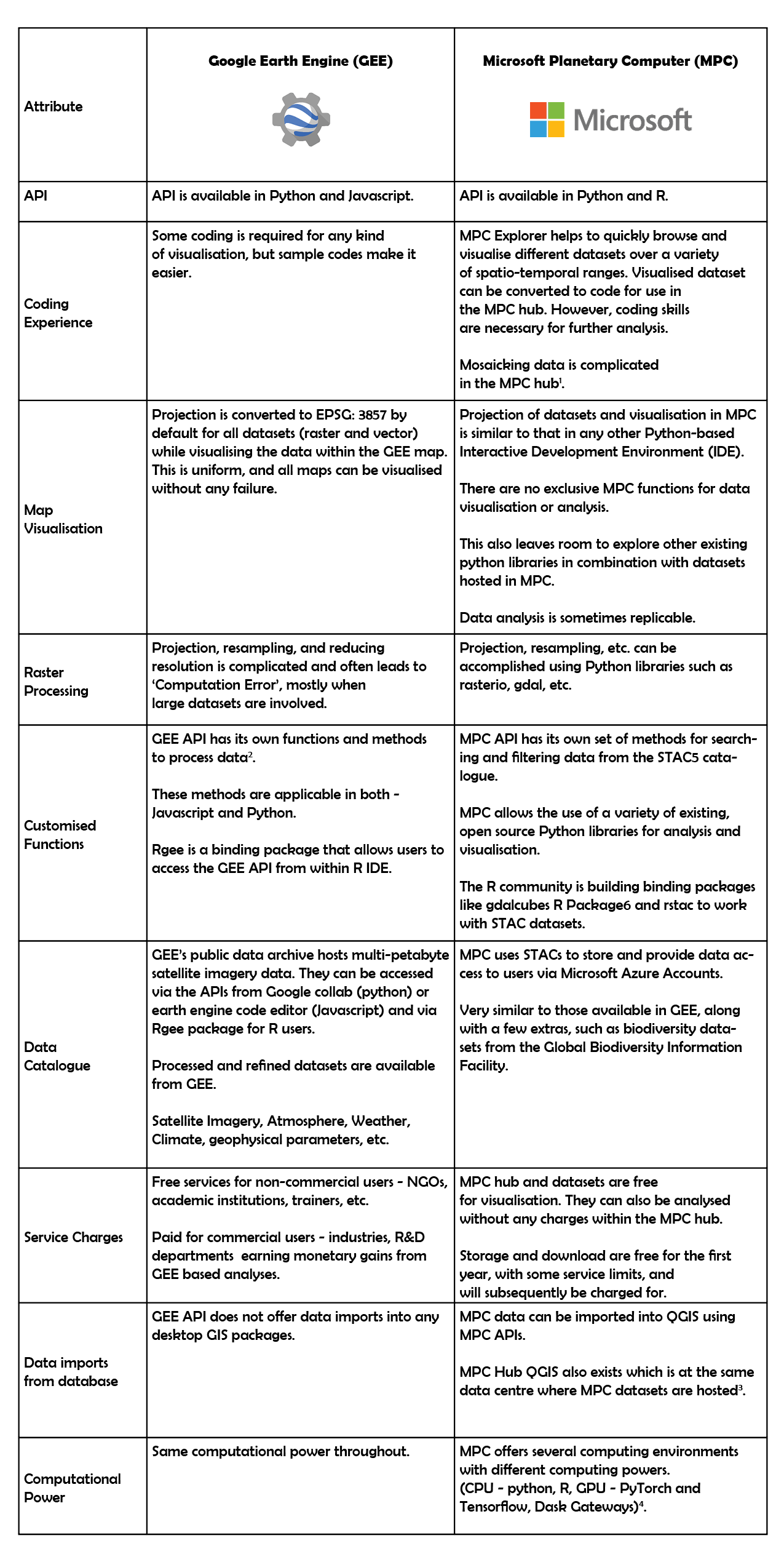
I viewed a spatially mosaicked dataset in MPC. However, one can download only individual images and not the mosaic of the area of interest. The ready-to-use codes for individual images are generated at MPC Explorer which can be used to view the image in MPC Hub. I also tried mosaicking the Sentinel dataset manually in MPC hub using this tutorial which uses GDAL’s ‘build VRT’ function. The tutorial used the National Agriculture Imagery Program (NAIP) dataset. However, the GDAL ‘build vrt’ code failed to work on the Sentinel dataset, as Sentinel and NAIP datasets are stored in different hierarchical formats.
Customised functions make basic raster and vector processing easy, thereby enhancing user experience.
The MPC datasets can be visualised and analysed using QGIS tools within MPC without the need to download them.
Users can create Dask Gateways or switch to different computing environments based on their task to scale the computation and fasten the process. This needs coding experience, and it is not automated. Users decide which is the best environment for their task.
STAC - Spatio-temporal Asset catalogue - a commonplace for users to look for spatial data. This was created to have a common code for accessing all spatial datasets.
“gdalcubes” is a library to represent collections of Earth Observation (EO) data. Data cubes may be simply exported as NetCDF files or directly streamed into external software such as R or Python. gdalcubes is not a database instead simply links to existing files / GDAL datasets - Source
I believe that when trying to compute large datasets, MPC has an advantage over GEE, as it provides access to different environments with a range of available computational power. The familiarity of using known Python and R libraries for analyses can be comforting for experienced users. On the other hand, I realised that all datasets in MPC are not homogeneously stored, and thus the code to extract & manipulate data may not be applicable to all datasets uniformly. While MPC is very useful for specific use cases, it will become even more useful when the planned introduction of customised raster and vector data manipulation functions is completed.
With regards to GEE, existing tutorials, extensive documentation and more customizability make tasks such as visualisation, storage, conversion between spatial data formats, raster and vector functions (such as mosaic and clip), easier for me than in the newer MPC. The most important utility is the flexibility to download analyses in GEE as this makes the data publishable and replicable. Bulky tasks like supervised classification are also less time consuming in GEE than in desktop GIS because of customised functions. While GEE requires minimal coding experience, most MPC tasks seem to be available only to skilled professionals at this point.
In conclusion, I’d like to caveat this article with the fact that at the time of writing, I have more experience using GEE than MPC, and I’m sure I haven’t explored the full capabilities of both platforms. Suggestions or comments are welcome; please get in touch via our contact form.