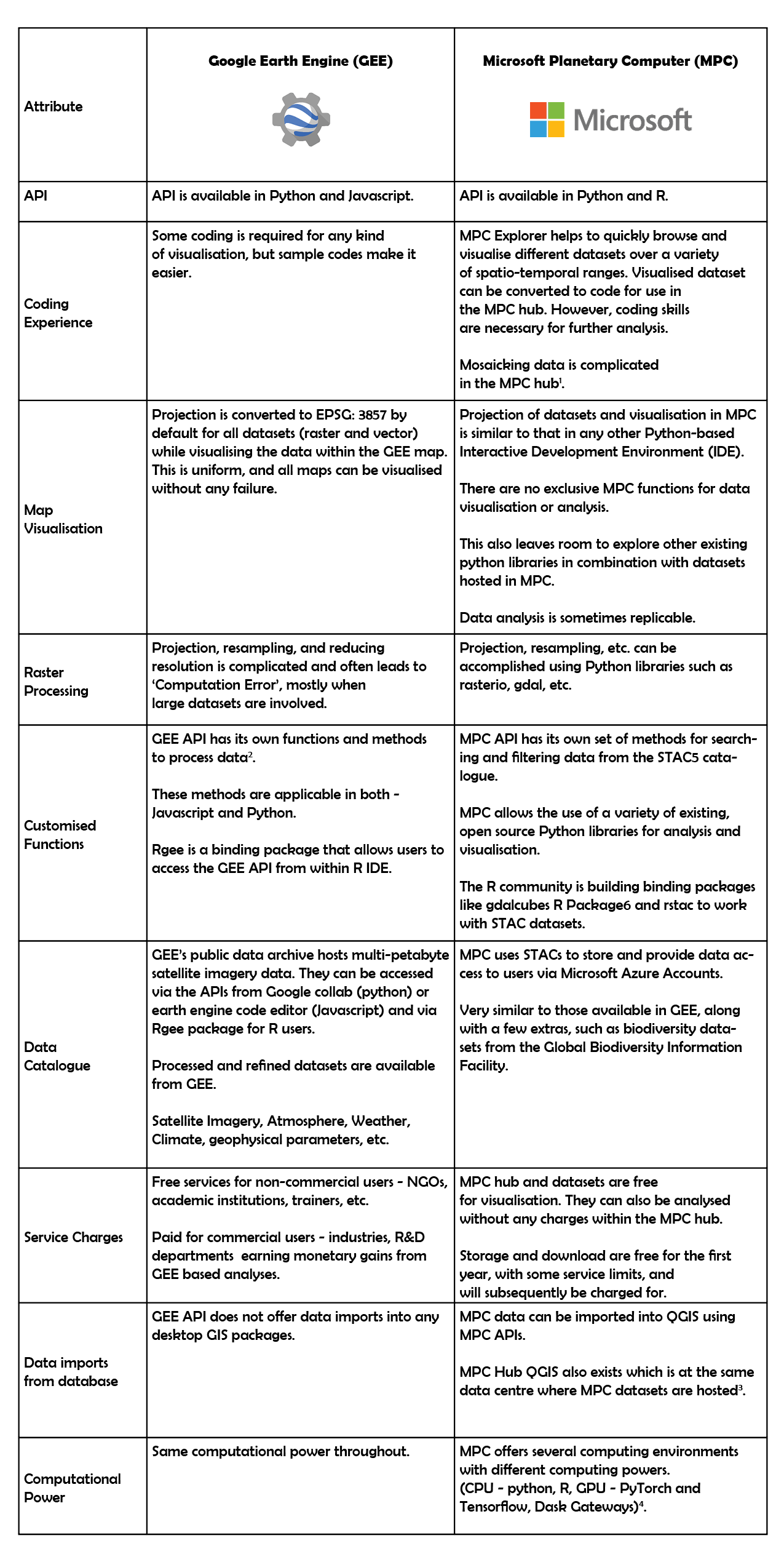
As part of our collaboration with Mongabay-India, we have utilised spatial analysis and visualisation to accompany their reporting. In June 2023, they published an explainer by Vinaya Kurtkoti on floodplains and their management in India. Their article discusses the ongoing process of concretisation and development in floodplains, which reduces the carrying capacity of rivers, leading to urban flooding.
We received information from the Mongabay-India team on urban floods in different parts of India. The data spanned periods exceeding ten years as well as recent occurrences. The task was to create maps of the areas before, during and after each flood event. Availability of suitable satellite imagery was key for creating these maps. This was a challenge as cloud cover during monsoon season - when the floods occurred was often 90% or more. Thus the initial, critical step towards creating these maps was to check if clear imagery existed for the required flood dates. Additionally, for events older than a decade, the issue of low resolution imagery arose. Initially we planned on showing the flood visually using the raw satellite images. Since we found no clear imagery for the flood dates, we had to look for other options that could depict the flood-prone areas.
Given the lack of clear imagery for the flood dates, I explored alternative approaches to represent flood-prone zones. Three distinct thresholding methods were experimented with, using three different platforms.
The first method involved utilising Digital Elevation Model (DEM) data in QGIS, an approach that came into play due to QGIS’s simple interface. By loading the area of interest through quick map services and employing the SRTM-downloader plugin, DEM 30m data was directly sourced from NASA Earthdata. I used the DEM data to establish a threshold. This method is a prediction of flood prone areas, given the level of water level rise. I looked for sources like news articles that reported the water level when the areas were flooded. I set that water level as the threshold using the raster calculator. By setting that threshold the algorithm gave the areas based on the elevation that would be inundated, if water level rises to a certain level.

Thresholding flood level from SRTM DEM data.
The second method I tried was using Sentinel-1 Synthetic Aperture Radar (SAR) data, which was available for the exact date when the flooding occurred in this area, using Google Earth Engine (GEE).
I then analysed pixel values of water by comparing images before and during flooding. Applying a pixel value threshold allowed for identification of sudden changes indicative of flooding. I began by filtering the pre-flood and post-flood dates for the images for Mahad city. So, I had two SAR images: one before the flood and one when it was flooded. I checked the pixel values of the water bodies before the flood from various spots. This pixel value was then set as the threshold. Once I input the threshold and ran the code, GEE highlighted areas with sudden pixel value changes of water bodies in the after image, indicating flood, and those with no change were the existing water bodies.

Pixel value change of the area marked in red from pre-flood to flood date in the Inspector display box.
The third threshold method I employed was for the Commonwealth Game Village area of Delhi. Initially, we hoped to depict actual visuals of the flooding in one of the areas using satellite imagery. However, demarcating the flood manually for the viewers to clearly differentiate between the pre and post-flood imagery was not possible because clear imagery was not available for the flood dates. When working with older satellite images dating back to 2010, we faced issues stemming from their low spatial resolution. This limitation arose because satellites with enhanced spatial resolutions were launched only after that time, in 2013. In order to show a similar situation, we searched for similar events in recent years and found images from 2022’s flood in Delhi. However, satellite images during the flood were still not useful because of the high cloud cover in them. So I had to look for images just after the flood event when the cloud cover was low but was still indicative of flood, as it takes time for the water to drain away.
Initially I tried the same method as before, by using SAR data. However, it seemed to detect built up areas like roads instead of water. Therefore I switched to Sentinel-2 L2A data for this region. According to Bhangale et al., 2020 [1] and Lekhak et al., 2023 [2] band 8 (NIR) with band 3 (Green) of Sentinel-2 could be used to identify water bodies. I therefore used the band 8 from both the pre and post-flood images to detect inundation. I checked the pixel values from various spots and noted down an approximate minimum and maximum pixel value of the water body in the image before the flood. This range was then used to differentiate water from non-water areas in post-flood images. After noting the values, I classified this range of values into one category as water and rest as not-water. I similarly applied this step in the post flood image which gave me the change in the water bodies which are the areas that were inundated.

Checking pixel values of water bodies from pre-flood images.

Setting threshold values to classify water and not-water.

Results after classification.
After applying all the three thresholding methods the question that arises is of their accuracy. While the first method that I applied was a prediction based on elevation and level of water, the other two methods were entirely based on satellite data.
In the case of Mahad, the first method based on elevation seemed to match the level of inundation to some extent with the SAR output, as it predicted the major areas that were inundated. SAR data, as per existing studies, is widely used and considered appropriate, for detecting floods as it is unaffected by cloud cover. This is because unlike other optical satellite imagery it is able to differentiate land and water contrast easily. However, SAR data [3] can sometimes misclassify shadows of tarmac areas with buildings and roads as water. This issue became evident when I experimented with SAR data in the Delhi case.
On the other hand, Sentinel-2 data gave results similar to the SAR output where built-up areas were misclassified as water. Sentinel-2 data is affected by atmospheric conditions unlike SAR. The process of setting pixel values is more manual, which can be affected by individual judgement, potentially leading to underestimation or overestimation[2].
Sentinel-1 SAR data has been found to have more accuracy in detecting floods than Sentinel 2. A study by Nhangumbe et al., 2023 [4] suggests combining both the data for attaining higher overall accuracy.
Overall all three methods provided estimations of the major areas that were inundated or likely to be inundated, fulfilling the purpose of the issue that Mongabay-India wished to convey. Meanwhile, the scope for exploration and improvement remains open!
References
Bhangale, U., More, S., Shaikh, T., Patil, S., & More, N. (2020). Analysis of Surface Water Resources Using Sentinel-2 Imagery. Procedia Computer Science, 171, 2645–2654. (https://doi.org/10.1016/j.procs.2020.04.287)
Lekhak, K., Rai̇, P., & Budha, P. B. (2023). Extraction of Water Bodies from Sentinel-2 Images in the Foothills of Nepal Himalaya. International Journal of Environment and Geoinformatics, 10(2), 70–81.(https://doi.org/10.30897/ijegeo.1240074)
Rahman, Md. R., & Thakur, P. K. (2018). Detecting, mapping and analysing of flood water propagation using synthetic aperture radar (SAR) satellite data and GIS: A case study from the Kendrapara District of Orissa State of India. The Egyptian Journal of Remote Sensing and Space Science, 21, S37–S41. (https://doi.org/10.1016/j.ejrs.2017.10.002)
Nhangumbe, M., Nascetti, A., & Ban, Y. (2023). Multi-Temporal Sentinel-1 SAR and Sentinel-2 MSI Data for Flood Mapping and Damage Assessment in Mozambique. ISPRS International Journal of Geo-Information, 12(2), 53.(https://doi.org/10.3390/ijgi12020053)